
새로운 데이터가 주어졌을 때, 가장 가까운 K개의 훈련 데이터(이웃)를 찾는 알고리즘.
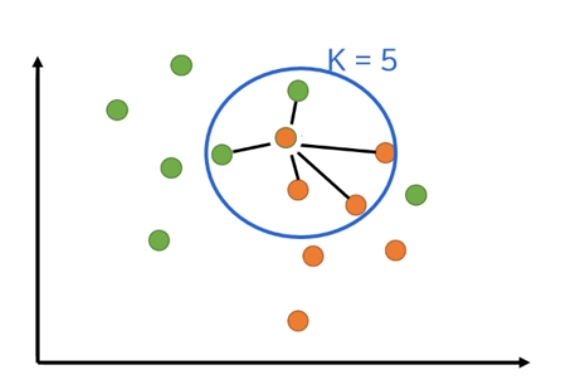
KNN 알고리즘은 분류와 회귀 문제를 모두 다룰 수 있는 알고리즘이다.
분류 : 다수결로 예측
회귀 : 평균 값으로 결과 예측
* 주요이슈
1. 데이터 간의 거리는 어떻게 측정?
유클리디안, 맨해튼, 민코프스키 거리 측정법 중에서 선택한다.
2. 적절한 K값의 크기는 어떻게 설정?
너무 작으면 민감도가 높아져서 잘못 예측할 확률이 높아진다.
너무 크면 예측이 둔감해진다.
결국, 최적의 k값을 찾는 것이 쉽지않다.
* 하이퍼파라미터(Hyper parameter) ex) 거리 계산 방식, K값
학습 시작 전에 모델러에 의해 결정되는 값.
모델의 성능에 영향을 주기에 최적의 값을 찾아 설정해야함.
* KNN 알고리즘
매우 단순하고 직관적인 알고리즘.
실행 시점에 K값에 의한 거리 연산 발생(고비용).
최적의 K값 정의가 중요함.
데이터의 스케일이 서로 다른 경우 별도의 정규화 과정 필요.

'프로젝트 > 코드프레소 체험단' 카테고리의 다른 글
| 파이썬으로 시작하는 머신러닝 - 데이터전처리 (0) | 2022.01.13 |
|---|---|
| 파이썬으로 시작하는 머신러닝 - 과대적합과 과소적합 (0) | 2022.01.11 |
| 파이썬으로 시작하는 머신러닝 - 머신러닝의 주요 프로세스 (0) | 2022.01.09 |
| 파이썬으로 시작하는 머신러닝 - 머신러닝의 분류 (0) | 2022.01.09 |
| 코드프레소 체험단을 시작하며 (0) | 2022.01.06 |
새로운 데이터가 주어졌을 때, 가장 가까운 K개의 훈련 데이터(이웃)를 찾는 알고리즘.
KNN 알고리즘은 분류와 회귀 문제를 모두 다룰 수 있는 알고리즘이다.
분류 : 다수결로 예측
회귀 : 평균 값으로 결과 예측
* 주요이슈
1. 데이터 간의 거리는 어떻게 측정?
유클리디안, 맨해튼, 민코프스키 거리 측정법 중에서 선택한다.
2. 적절한 K값의 크기는 어떻게 설정?
너무 작으면 민감도가 높아져서 잘못 예측할 확률이 높아진다.
너무 크면 예측이 둔감해진다.
결국, 최적의 k값을 찾는 것이 쉽지않다.
* 하이퍼파라미터(Hyper parameter) ex) 거리 계산 방식, K값
학습 시작 전에 모델러에 의해 결정되는 값.
모델의 성능에 영향을 주기에 최적의 값을 찾아 설정해야함.
* KNN 알고리즘
매우 단순하고 직관적인 알고리즘.
실행 시점에 K값에 의한 거리 연산 발생(고비용).
최적의 K값 정의가 중요함.
데이터의 스케일이 서로 다른 경우 별도의 정규화 과정 필요.
'프로젝트 > 코드프레소 체험단' 카테고리의 다른 글
| 파이썬으로 시작하는 머신러닝 - 데이터전처리 (0) | 2022.01.13 |
|---|---|
| 파이썬으로 시작하는 머신러닝 - 과대적합과 과소적합 (0) | 2022.01.11 |
| 파이썬으로 시작하는 머신러닝 - 머신러닝의 주요 프로세스 (0) | 2022.01.09 |
| 파이썬으로 시작하는 머신러닝 - 머신러닝의 분류 (0) | 2022.01.09 |
| 코드프레소 체험단을 시작하며 (0) | 2022.01.06 |