프로젝트/코드프레소 체험단
시계열 데이터 처리를 위한 RNN 완벽 가이드 - 영화리뷰 데이터셋 분류 모델 구현
KimCookieYa
2022. 3. 20. 18:05
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
print(tf.__version__)
""" Input tensor와 Target tensor 준비(훈련 데이터) """
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=10000)
print(len(input_train))
# 25000
print(input_train.shape)
# (25000,)
# 媛� 由ъ뒪�듃�쓽 湲몄씠媛� �떖�씪�꽌, �몴�쁽�븯吏� 紐삵븳�떎.
""" 입력 데이터의 전처리
- RNN 모델에 데이터를 입력하기 위해 시퀀스 데이터의 길이를 통함
"""
input_train = sequence.pad_sequences(input_train, maxlen=800)
input_test = sequence.pad_sequences(input_test, maxlen=800)
print(input_train.shape)
# (25000, 800)
""" RNN 모델 디자인
- embedding layer: 32차원
- hidden layer: 1개(32)
- activation: tanh
"""
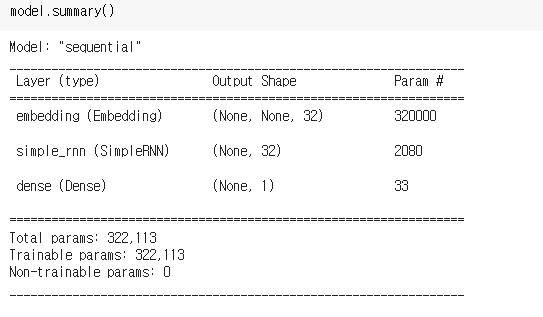
model = models.Sequential()
model.add(layers.Embedding(input_dim=10000, output_dim=32))
model.add(layers.SimpleRNN(units=32, activation='tanh'))
model.add(layers.Dense(units=1, activation='sigmoid'))
model.summary()
""" 모델의 학습 정보 설정
- loss: binary crossentropy
- optimiizer: rmsprop
- metric: accuracy
"""
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics='acc')
""" 모델에 input, target 데이터 연결 후 학습
- batch size: 128
- epochs: 10
- validation data set percent: 20%
"""
history = model.fit(x=input_train, y=y_train, batch_size=128, epochs=10, validation_split=0.2)
""" 학습과정의 시각화 및 성능 테스트 """
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'b', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
""" 테스트 데이터 셋을 통한 성능 측정"""
test_loss, test_acc = model.evaluate(x=input_test, y=y_test)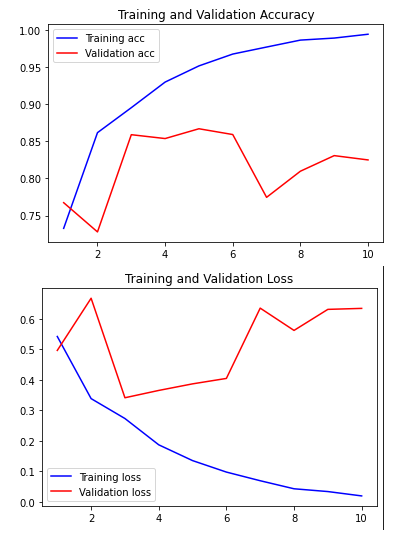

* overfitting이 발생해, validation datasets에 대해 성능이 좋지 않은 것을 확인할 수 있음.
* test dataset에 대한 accuracy는 0.8134로 좋지 않음.
